Container security
Page last updated:
This topic tells you about how Cloud Foundry Application Runtime secures the containers that host app instances on Linux.
For an overview of other Cloud Foundry security features, see Cloud Foundry Security.
The sections in this topic provide the following information:
Container Mechanics provides an overview of container isolation.
Inbound and Outbound Traffic from Cloud Foundry provides an overview of container networking and describes how Cloud Foundry admins customize container network traffic rules for their deployment.
Container Security describes how Cloud Foundry secures containers by running app instances in unprivileged containers and by hardening them.
Container mechanics
Each instance of an app deployed to Cloud Foundry runs within its own self-contained environment, a Garden container. This container isolates processes, memory, and the filesystem using operating system features and the characteristics of the virtual and physical infrastructure where Cloud Foundry is deployed. For more information about Garden containers, see Garden.
Cloud Foundry achieves container isolation by namespacing kernel resources that would otherwise be shared. The intended level of isolation is set to prevent multiple containers that are present on the same host from detecting each other. Every container includes a private root filesystem, which includes a Process ID (PID), namespace, network namespace, and mount namespace.
Cloud Foundry creates container filesystems using the Garden Rootfs (GrootFS) tool. It stacks the following using OverlayFS:
A read-only base filesystem: This filesystem has the minimal set of operating system packages and Garden-specific modifications common to all containers. Containers can share the same read-only base filesystem because all writes are applied to the read-write layer.
A container-specific read-write layer: This layer is unique to each container and its size is limited by XFS project quotas. The quotas prevent the read-write layer from overflowing into unallocated space.
For more information about GrootFS, see Garden RootFS (GrootFS) in Garden.
Resource control is managed using Linux control groups. Associating each container with its own cgroup or job object limits the amount of memory that the container might use. Linux cgroups also require the container to use a fair share of CPU compared to the relative CPU share of other containers.
Cloud Foundry does not support a RedHat Enterprise Linux OS stemcell. This is due to an inherent security issue with the way RedHat handles user namespacing and container isolation.
CPU
Each container is placed in its own cgroup. Cgroups make each container use a fair share of CPU relative to the other containers. This prevents oversubscription on the host VM where one or more containers hog the CPU and leave no computing resources to the others.
The way cgroups allocate CPU time is based on shares. CPU shares do not work as direct percentages of total CPU usage. Instead, a share is relative in a given time window to the shares held by the other containers. The total amount of CPU that can be overall divided among the cgroups is what is left by other processes that might run in the host VM.
Generally, cgroups offers two possibilities for limiting the CPU usage: CPU affinity and CPU bandwidth, the latter of which is used in Cloud Foundry.
CPU affinity consists of binding a cgroup to certain CPU cores. The actual amount of CPU cycles that can be consumed by the cgroup is thus limited to what is available on the bound CPU cores.
CPU bandwidth sets the weight of a cgroup with the process scheduler. The process scheduler divides the available CPU cycles among cgroups depending on the shares held by each cgroup, relative to the shares held by the others. For example, consider two cgroups, one holding two shares and one holding four. Assuming the process scheduler gets to administer 60 CPU cycles, the first cgroup with two shares will get one third of those available CPU cycles, as it holds one third of the overall shares. Similarly, the second cgroup will get 40 cycles, as it holds two thirds of the collective shares.
The calculation of the CPU usage based on the percentage of the total CPU power available is quite sophisticated and is performed regularly as the CPU demands of the various containers fluctuates. Specifically, the percentage of CPU cycles a cgroup gets can be calculated by dividing the cpu.shares it holds by the sum of the cpu.shares of all the cgroups that are currently doing CPU activity, as shown in the following calculation:
process_cpu_share_percent = cpu.shares / sum_cpu_shares * 100
In Cloud Foundry, cgroup shares range from 10 to 1024. The actual number of shares a cgroup gets can be read from the cpu.shares file of the cgroup configurations pseudo-file-system available in the container at /sys/fs/cgroup/cpu. The number of shares given to an apps cgroup depends on the amount of memory the app declares to need in the manifest.
CPU Shares Algorithm 1
When the Diego containers.set_cpu_weight bosh property is set to false, then Cloud Foundry scales the number of allocated shares linearly with the amount of memory, until the upper limit of 1024 shares (by default).
In this case, there are a handful of variables that play into the CPU shares calculation.
| variable name | default value | configurable? | link to property |
|---|---|---|---|
| cc.cpuweightmin_memory | 128 | yes | bosh property |
| cc.cpuweightmax_memory | 8192 | yes | bosh property |
| appmemoryin_mb | 1024 | yes | this is set in the app manifest |
| base_weight | 8192 | no | n/a |
| diego.executor.containermaxcpu_shares | 1024 | yes | bosh property |
These variables are used in the following algorithm to determine the number of CPU shares for an app:
app_memory_for_calculation = min( max(cc.cpu_weight_min_memory, app_memory_in_mb), cc.cpu_weight_max_memory)
app_cpu_weight = int( (100 * app_memory_for_calculation) / base_weight)
process_cpu.shares = int( (diego.executor.container_max_cpu_shares * app_cpu_weight) / 100)
For example:
cc.cpu_weight_min_memory = 128
cc.cpu_weight_max_memory = 8192
app_memory_in_mb = 32
base_weight = 8192
diego.executor.container_max_cpu_shares = 1024
app_memory_for_calculation = min(max(cc.cpu_weight_min_memory, app_memory_in_mb)
app_memory_for_calculation = min(max(128, 32), 8192) = min(128, 8192) = 128
app_cpu_weight = int((100 * app_memory_for_calculation)/base_weight))
app_cpu_weight = int((100 * 128) / 8192) = int(12800 / 8192) = int(1.56) = 1
process_cpu.shares = int( (diego.executor.container_max_cpu_shares * app_cpu_weight) / 100)
process_cpu.shares = int( (1024 * 1) / 100) = int(10.24) = 10
CPU Shares Algorithm 2
When the Diego containers.setcpuweight BOSH property is set to true, then Cloud Foundry scales the number of allocated shares linearly with the amount of memory
In this case, there are two variables that play into the CPU shares calculation.
| variable name | default value | configurable? | link to property |
|---|---|---|---|
| appmemoryin_mb | 1024 | yes | this is set in the app manifest |
| containers.proxy.additionalmemoryallocation_mb | 32 | yes | bosh property |
In this case, the following algorithm is used to determine the number of CPU shares for an app:
process_cpu.shares = app_memory_in_mb + containers.proxy.additional_memory_allocation_mb
CPU Share Interaction
The next example helps to illustrate this better. Consider three processes: P1, P2 and P3, which are assigned cpu.shares of 5, 20 and 30, respectively.
P1 is active, while P2 and P3 require no CPU. Hence, P1 might use the whole CPU. When P2 joins in and is doing some actual work, such as when a request comes in, the CPU share between P1 and P2 is calculated as follows:
- P1 -> 5 / (5+20) = 0.2 = 20%
- P2 -> 20 / (5+20) = 0.8 = 80%
- P3 (idle)
At some point, process P3 joins in. Then the distribution is recalculated again:
- P1 -> 5 / (5+20+30) = 0.0909 = ~9%
- P2 -> 20 / (5+20+30) = 0.363 = ~36%
- P3 -> 30 / (5+20+30) = 0.545 = ~55%
If P1 become idle, the following recalculation between P2 and P3 takes place:
- P1 (idle)
- P2 -> 20 / (20+30) = 0.4 = 40%
- P3 -> 30 / (20+30) = 0.6 = 60%
If P3 finishes or becomes idle, then P2 can consume all the CPU, as another recalculation is performed.
In summary, the cgroup shares are the minimum guaranteed CPU share that the process can get. This limitation becomes effective only when processes on the same host compete for resources.
Inbound and outbound traffic from Cloud Foundry
Learn about container networking and how Cloud Foundry admins customize container network traffic rules for their deployment.
Networking overview
A host VM has a single IP address. If you configure the deployment with the cluster on a VLAN, as Cloud Foundry recommends, then all traffic goes through the following levels of network address translation, as shown in the following diagram:
Inbound requests flow from the load balancer through the router to the host Diego Cell, then into the app container. The router determines which app instance receives each request.
Outbound traffic flows from the app container to the Diego Cell, then to the gateway on the Diego Cell’s virtual network interface. Depending on your IaaS, this gateway might be a NAT to external networks.
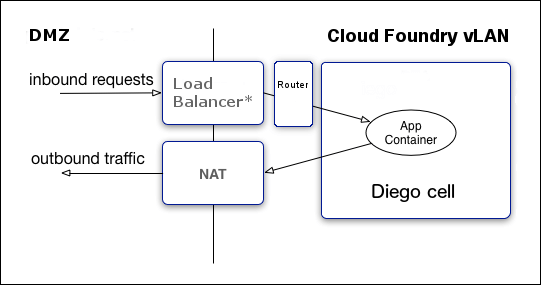
The networking diagram shows the following:
Inbound requests go to Load Balancer
Outbound traffic comes from NAT
Cloud Foundry vLAN (on right side):
Load balancer goes to router and to the app container inside the Diego Cell
App container response goes to NAT
Network traffic rules
Admins configure rules to govern container network traffic. This is how containers send traffic outside of Cloud Foundry and receive traffic from outside, the Internet. These rules can prevent system access from external networks and between internal components and determine if apps can establish connections over the virtual network interface.
Admins configure these rules at two levels:
Application Security Groups (ASGs) apply network traffic rules at the container level. For more information about ASGs, see the Application Security Groups topic.
Container-to-container networking policies determine app-to-app communication. Within Cloud Foundry, apps can communicate directly with each other, but the containers are isolated from outside Cloud Foundry. For information about administering container-to-container network policies, see Configuring Container-to-Container Networking.
Container security
Cloud Foundry secures containers through the following measures:
Running app instances in unprivileged containers by default. For more information about app instances, see Types.
Hardening containers by limiting function and access rights. For more information about hardening containers, see Hardening.
Only allowing outbound connections to public addresses from application containers. This is the original default. Administrators can change this behavior by configuring ASGs. For more information about ASGs, see the Application Security Groups topic.
Types
Garden has the following container types:
- unprivileged
- privileged
Currently, Cloud Foundry runs all app instances and staging tasks in unprivileged containers by default. This measure increases security by eliminating the threat of root escalation inside the container.
Although all application instances and staging tasks now run by default in unprivileged containers, operators can override these defaults by customizing their Diego deployment manifest and redeploying.
- To enable privileged containers for buildpack-based apps, set the
cc.diego.use_privileged_containers_for_runningproperty totruein the Diego manifest (default isfalse). - To enable privileged containers for staging tasks, set the
cc.diego.use_privileged_containers_for_stagingproperty totruein the Diego manifest (default isfalse).
Hardening
Cloud Foundry mitigates against container breakout and denial of service attacks in the following ways:
Cloud Foundry uses the full set of Linux namespaces - IPC, Network, Mount, PID, User, UTS - to provide isolation between containers running on the same host. The User namespace is not used for privileged containers. For more information about Linux namespaces, see namespaces - overview of Linux namespaces in the Ubuntu documentation.
In unprivileged containers, Cloud Foundry maps UID/GID 0 (root) inside the container user namespace to a different UID/GID on the host to prevent an app from inheriting UID/GID 0 on the host if it breaks out of the container.
- Cloud Foundry uses the same UID/GID for all containers.
- Cloud Foundry maps all UIDs except UID 0 to themselves. Cloud Foundry maps UID 0 inside the container namespace to
MAX_UID-1outside of the container namespace. - Container Root does not grant Host Root permissions.
Cloud Foundry mounts
/procand/sysas read-only inside containers.Cloud Foundry disallows
dmesgaccess for unprivileged users and all users in unprivileged containers.Cloud Foundry uses
chrootwhen importing docker images from docker registries.Cloud Foundry establishes a container-specific overlay filesystem mount. Cloud Foundry uses
pivot_rootto move the root filesystem into this overlay, in order to isolate the container from the host system’s filesystem. For more information aboutpivot_root, see pivot_root - change the root filesystem in the Ubuntu documentation.Cloud Foundry does not call any binary or script inside the container filesystem, in order to eliminate any dependencies on scripts and binaries inside the root filesystem.
Cloud Foundry avoids side-loading binaries in the container through bind mounts or other methods. Instead, it runs the same binary again by reading it from
/proc/self/exewhenever it needs to run a binary in a container.Cloud Foundry establishes a virtual ethernet pair for each container for network traffic. For more information, see Container Network Traffic. The virtual ethernet pair has the following features:
- One interface in the pair is inside the container’s network namespace, and is the only non-loopback interface accessible inside the container.
- The other interface remains in the host network namespace and is bridged to the container-side interface.
- Egress allow list rules are applied to these interfaces according to ASGs configured by the admin.
- First-packet logging rules might also be activated on the TCP allow list rules.
- DNAT rules are established on the host to enable traffic ingress from the host interface to allowed ports on the container-side interface.
Cloud Foundry applies disk quotas using container-specific XFS quotas with the specified disk-quota capacity.
Cloud Foundry applies a total memory usage quota through the memory cgroup and destroys the container if the memory usage exceeds the quota.
Cloud Foundry applies a fair-use limit to CPU usage for processes inside the container through the
cpu.sharescontrol group.Cloud Foundry allows admins to rate limit the maximum bandwidth consumed by single-app containers, configuring
rateandburstproperties on thesilk-cnijob.Cloud Foundry limits access to devices using cgroups but explicitly allows the following safe device nodes:
/dev/full/dev/fuse/dev/null/dev/ptmx/dev/pts/*/dev/random/dev/tty/dev/tty0/dev/tty1/dev/urandom/dev/zero/dev/tap/dev/tun
Cloud Foundry drops the following Linux capabilities for all container processes. Every dropped capability limits the actions the root user can perform.
CAP_DAC_READ_SEARCHCAP_LINUX_IMMUTABLECAP_NET_BROADCASTCAP_NET_ADMINCAP_IPC_LOCKCAP_IPC_OWNERCAP_SYS_MODULECAP_SYS_RAWIOCAP_SYS_PTRACECAP_SYS_PACCTCAP_SYS_BOOTCAP_SYS_NICECAP_SYS_RESOURCECAP_SYS_TIMECAP_SYS_TTY_CONFIGCAP_LEASECAP_AUDIT_CONTROLCAP_MAC_OVERRIDECAP_MAC_ADMINCAP_SYSLOGCAP_WAKE_ALARMCAP_BLOCK_SUSPENDCAP_SYS_ADMINfor unprivileged containers
For more information about Linux capabilities, see capabilities - overview of Linux capabilities in the Ubuntu documentation.